
Olá pessoal! No dia 13/03/2022, ocorreu a prova do TCU. Certamente um dia inesquecível no mundo dos concursos, por vários fatores os quais estarão expostos mais ao final deste artigo.
A partir de agora irei analisar a parte de Análise de Dados utilizando como base a prova branca. Para as questões de Banco de Dados, em serei bem rasteiro, pois a correção ficou a cargo do Professor Gabriel Pacheco, cujo link para a correção detalhada estará aqui em breve. Meu foco aqui será a parte de PLN, Machine Learning e programação, certamente a parte mais polêmica de toda a prova.

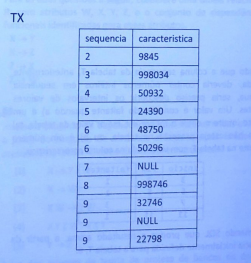




Resolução:
Esta questão de SQL foi resolvida e analisada pelo Professor Gabriel Pacheco, segundo os resultados obtidos por ele a resposta correta é a letra D.
Resposta: D






Resolução:
Pela resolução do Professor Gabriel, o código que retorna a tabela apresentada é a alternativa B.
Resposta: B

Resolução:
Segundo o professor Gabriel, quando separados em grupos homogêneos, haveria apenas um grupo.
Resposta: A

Resolução:
Questão um tanto complicada. Primeiro vamos entender a função.
A função traz um condicional onde é retornado apenas valores de k que seja par. Perceba que nesta função não temos o return, aqui é utilizado a yield. O yield é utilizado para retornar geradores. Isto permitirá a execução reiterada de todos os elementos da lista.
Já na segunda parte é criada uma lista e esta lista é passada para a função xpto como S[::-1]. Escrito desta forma, a lista é passada como parâmetro de forma invertida, [6,5,4,3,2,1].
De fato, a lógica da função é retornar o próprio valor quando o número da posição do elemento na lista (invertida) é par, pois tem resto zero na divisão por dois.
Quando olhamos para a lista invertida o valor de S[0] = 6, S[2] = 4 e S[4] = 2.
Como um primeiro parênteses, destaco que o conhecimento sobre geradores, iteradores e o próprio comando yield é algo bem avançado dentro da linguagem Python, não sendo sequer um conhecimento necessário para resolver a grande maioria dos problemas de machine learning atuais.
Resposta: C


Resolução:
Aqui precisamos entender mais o array que é retornado do que toda a função em si.
Primeiro é preciso entender que temos um array em que o valor 1 é verdadeiro e 0 é um valor falso.
A coluna 0 do array representa a marca de carro BMW, a coluna 1 representa a marca de carro Toyota, a coluna 2 representa a cor verde e a coluna 3 representa a cor vermelha.
Veja que na primeira linha do array é [0., 1., 0., 1.], sendo que é verdadeiro para Toyota e Vermelho e falso pra BMW e Verde, e a partir desse entendimento que devemos continuar a resolução.
Natasha quer chegar ao valor 2, que é o valor correspondente a quantidade de carros Toyota que há na base de dados.
Para isso é possível somar os elementos da coluna 1, visto que esta coluna é referente a marca Toyota e sempre que o valor for verdadeiro corresponde ao valor 1.
O código a ser digitado deve ser sum(X_prime)[1].
Resposta: D


Resolução:
Esta foi outra questão analisada pelo professor Gabriel, e segundo sua análise somente a 1,2,3 e 4 são válidas, sendo somente a 5 invalidada.
Resposta: C

Resolução:
Para o professor Gabriel a alternativa para esta questão é a alternativa B, porém ele acredita que o gabarito oficial venha como alternativa A, e vindo como alternativa A cabe recurso.
Aqui temos uma das chaves que seria candidata e que para a forma normal de Boyce_Codd não pode acontecer.
Resposta: B*

Resolução:
Aqui temos o famoso knn (K – nearest neightbors), que vimos e fizemos exercícios em aula.
Vendo o conjunto de dados podemos ver que existem apenas duas classes, A e B.
Neste exercício era necessário criar um plano cartesiano com os pontos referentes a cada classe.
Depois de colocar os pontos no plano cartesiano criado, deve-se locar os novos pontos (1,1), (0,0) e (-1,2), e contar, dentre os vizinhos mais próximos, se a maioria serão da classe A ou B. Ao fazê-lo, veremos que os dois primeiros pontos serão preditos como também sendo da categoria A, enquanto o último será predito como da categoria B.
Resposta: D

Resolução:
Um caminho para resolver a questão era analisar os condicionais apresentados nas alternativas, com seus respectivos valores, e comparar com a resposta observada. Vamos ver o retorno para cada uma das alternativas.
(A) “Sim”, “Não”, “Sim”, “Não”
(B) “Sim”, “Não”, “Sim”, “Não”
(C) “Sim”, “Sim”, “Sim”, “Não”
(D) “Não”, “Sim”, “Não”, “Não”
(E) “Sim, “Sim”, “Sim”, “Sim”
Pareceu mais um problema de atenção (e observação) do que um problema de classificação em si…
Resposta: B

Resolução:
Tendo os valores dos pesos w1 e w2 que multiplicam, respectivamente, x1 e x2, além do viés w0 temos a seguinte função:
z(x1,x2) = w1*x1+ w2*x2 + w0 = 2*x1 + 3*x2 +1
Dado um par de valores x1 e x2, z(x1,x2), nossa função de ativação, terá algum resultado. Caso z>=0, S(z) será 1, e se z<0, S(z) será -1.
O objetivo do exercício é saber quais valores de x1 e x2 formam a reta limítrofe do sinal, ou seja, qual o limite para valores de x1 e x2 de modo que seja possível saber S(z) somente locando um ponto (x1,x2) no plano cartesiano.
Para tal, deve-se zerar x1 e saber qual valor de x2 zera z, e zerar x2 para saber qual valor de x1 zera z.
Para x1:
0 = 2×1 + 1
x=-1/2
Para x2:
0 = 3×2 +1
x2 = -1/3
Para valores acima desse par, z será maior que 0 e S(z) será +1.
Resposta: C

Resolução:
Essa questão é realmente bem confusa.
A minha lógica aqui foi buscar valores de alfa e beta mais equilibrados. Diante das alternativas, inicio a resolução pela alternativa C.
Escolho alfa como 40% (percentual de arquivos sigilosos) e beta como 60%(beta sendo a base de teste, e portanto 40% como base de treino). Neste cenário, o próximo passo é calcular qual o percentual de documentos sigilosos e públicos temos nas bases de treino e de teste.
Com 40% na base de treino, existe 16% de documentos sigilosos e 24% de documentos públicos. Já com 60% base de teste, teremos 24% de documentos sigilosos e 36% de documentos públicos, atendendo assim a expectativa de mínimo 10% do total de documentos sigilosos/públicos em cada uma das bases.
Somente para ilustrar uma alternativa fracassando na exigência do enunciado, peguemos a alternativa e), com 70% em alpha, e 20% na base de teste (ou seja, 80% na base de treino).
Ao realizar o “split” nas bases, perceba que, com 20% na base de teste, teremos 14% de documentos sigilosos e 6% de documentos públicos (divisão 70%/30%, com base em alpha). Ao ter menos do que 10% do total de documentos sigilosos na base de teste, a condição fracassa.
Resposta: C

Resolução:
Esse algoritmo LDA é empregado em uma biblioteca mais avançada que o NLTK. De fato, ele se encontra em sklearn.LDA.
Explicando o que é o LDA, é um método onde o algoritmo vai analisar um documento com as suas diversas palavras características e prever a qual tópico este documento pertence.
Digamos que há um documento que precisa ser classificado em algum tópico como economia, administração, computação, direito, etc.
Tendo o documento sendo lido pelo modelo este irá prever a possibilidade dele pertencer a alguma das categorias, por exemplo, digamos que após passar pelo modelo LDA o documento tem 5% de chance de ser de arte, 12% de ser sobre direito, 53% de probabilidade de ser de economia, enfim, estou só trazendo um exemplo com valores aleatórias, mas em suma é isso, ele mostra a probabilidade de um documento pertencer a uma categoria.
Em cada tópico existe uma cesta de palavra (bag of words) e cada palavra dentro do documento tem uma probabilidade de pertencer aos tópicos, de forma análoga ao próprio documento.
A ponderação das probabilidades de todas as palavras do documento em relação aos tópicos dirá a probabilidade global do documento de pertencer aos tópicos.
Resposta: E

Resolução:
Aqui temos a única questão de R, que diz respeito a pivotamento.
Dados é uma variável do tipo tibble, e aqui esta a relação dos Analistas A1, A2 e A3 e a relação de quantos processos por anos para cada um dos analistas.
O que ocorre no pivotamento é que quando se tem uma grande quantidade de dados ele é resumido.
Vamos olhar para a questão e entender o que é o pivotamento.
Perceba que A1, A2 e A3 aparecem diversas vezes na coluna Analista, o que a questão quer é pivotar em uma tabela na qual os analistas também sejam colunas. Desta forma, temos as colunas A1, A2 e A3, nas quais as colunas recebem os valores dos processos em relação a cada ano.
De fato, a nova tabela ficaria assim:
Ano – Analista_A1 – Analista_A2 – Analista_A3
2018 – 10 – NA – 8
2019 – 15 – 25 – 7
2020 – 20 – 20 – 12
Sendo assim, a primeira linha apresentaria o primeiro ano, no caso 2018 e os processos referentes a 2018 para cada analista.
O analista A1 em 2018 apresentou 10 processos, o analista A2 em 2018 não apresentou nenhum processo, e o analista A3 apresentou 8 processos em 2018, sendo assim, a primeira linha apresentada será:
2018,10, NA, 8.
Resposta: A

Resolução:
Uma matriz TF-IDF representa o peso de uma palavra em um determinado documento. Quanto mais documentos aparecer este termo, menor sua importância nos documentos e seu peso é penalizado tendendo a um valor baixo. Quanto menos o termo aparecer em um documento, mais importante ele é no documento em que aparece.
Esta matriz deve apresentar 6 elementos, sendo uma matriz 2×3, onde as linhas representam as sentenças A e B e as colunas apresentam as palavras “Rosas”, “Choram” e “Sorriem” respectivamente.
Agora analisando a palavra Rosas ela aparece nos dois documentos, portanto ela não apresenta nenhuma relevância, desta forma a coluna que representa a palavra Rosas será zerado.
Analisando a palavra “Choram” ela aparece apenas no primeiro documento, portanto ela só tem relevância na primeira linha, neste caso a segunda coluna deve ter alguma valor na primeira linha e deve estar zerado na segunda linha.
Analisando a palavra “Sorriem” ela aparece apenas no segundo documento, ou seja, só existe peso para ela na segunda linha, desta forma a coluna referente a palavra Sorriem terá a primeira linha nula e a segunda linha com um valor.
Desta forma a primeira linha deve ser [0 valor 0] e a segunda linha [0 0 valor].
A opção que mostra essa sequência numérica é a alternativa c. Intencionalmente desprezei o cálculo do TF-IDF para a questão.
Resposta: C

Resolução:
Aqui é preciso lembrar que quando há problema com duplicação de dados, relação entre diversas bases de dados para criação de uma base única de dados é utilizado o pareamento de dados.
O que nos deixa com a opção D e E, porém é preciso lembrar que pareamento de dados, no contexto da questão, será realizado em sistemas com dados estruturados.
Resposta: D

Resolução:
Esta questão estava bem fácil para quem conseguiu identificar escolha política como um identificador sensível, visto que é o único identificador sensível no exemplo b).
Identificadores explícitos são CPF, RG, CNH.
Identificadores sensíveis são escolha política, convicções religiosas, filosóficas, orientação sexual.
Quasi identificadores pode ser uma doença rara, que apesar que outras pessoas terem essa doença ainda é possível de identificar alguém por esta condição de saúde.
Resposta: C

Resolução:
Mais uma questão bem complicada!
Aqui o analista quer um modelo que seja compatível com sistema de caching.
De todas as opções, para mim, a alternativa correta é a D, visto que apenas Word2Vec e GloVe trabalham com estratégia de caching.
Quando vamos para as outras alternativas, podemos começar com TF-IDF que não é implementação mas é teoria, e BERT e GPT-2 não apresentam estratégias de caching.
Mas a minha dúvida é: em que ponto do edital seria possível entender que tais bibliotecas seriam cobradas em prova? Afinal, se é necessário ao candidato saber estratégia de caching, pelo menos as bibliotecas destes algoritmos deveria ser disponibilizada, não?
Resposta: D
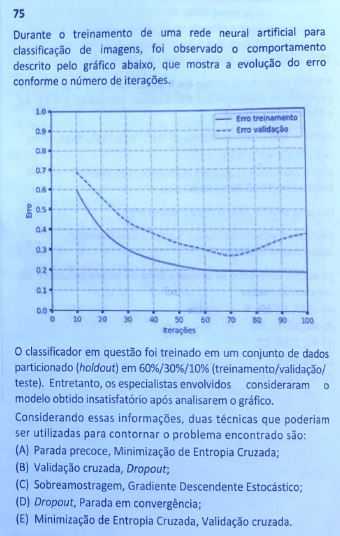
Resolução:
Outra questão extremamente complicada. Não se espera que FGV seja fácil, mas realmente ela se superou nesta prova.
Observando o gráfico é possível ver que no erro de treinamento é estabilizado em 60 iterações e que o erro de treinamento tem seu valor mínimo em 70 iterações.
Observando o gráfico, o que me parece mais plausível é a Parada Precoce, visto que o melhor é parar nas 70 iterações e a Minimização de Entropia Cruzada. No entanto, esta é uma questão que ainda não consolidei o meu entendimento.
Resposta: A*
Este é o gabarito extraoficial, mas sendo bem sincero com vocês, vou continuar estudando estas questões, vendo se houve extrapolação de conteúdo, ou qualquer outro elemento que justifique eventuais anulações.
Sinceramente, essa prova foi muito, muito, muito difícil. Parabéns a todos os sobreviventes.
Não deixe de voltar aqui depois do gabarito preliminar, ou me procurar no Instagram @profvictordalton, pois tenho certeza que ainda teremos muito o que debater.
